*전체적인 C++ 컴파일 과정
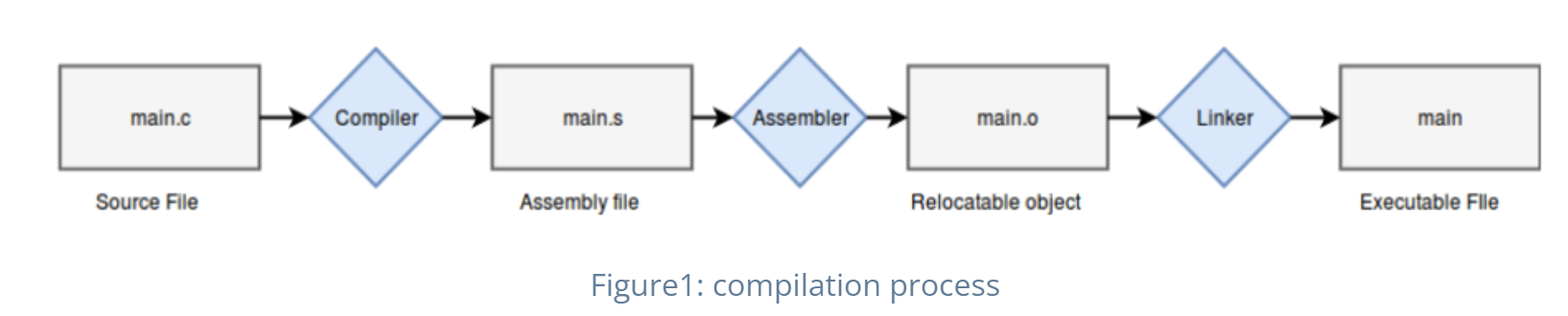
1. 전처리 단계
=> #include, #define .... 전처리기 매크로들을 처리.
2. 컴파일 단계
=> 소스파일들을 어셈블리 명령어로 변환.
3. 어셈블 단계
=> 실제 기계어로 이루어진 목적 코드 (.obj) 로 변환.
4. 링킹 단계
=> 목적 코드 ( obj ) 들을 하나로 모아 실행 파일 생성.
*전처리 단계
1. 문자 해석하기
translation character set
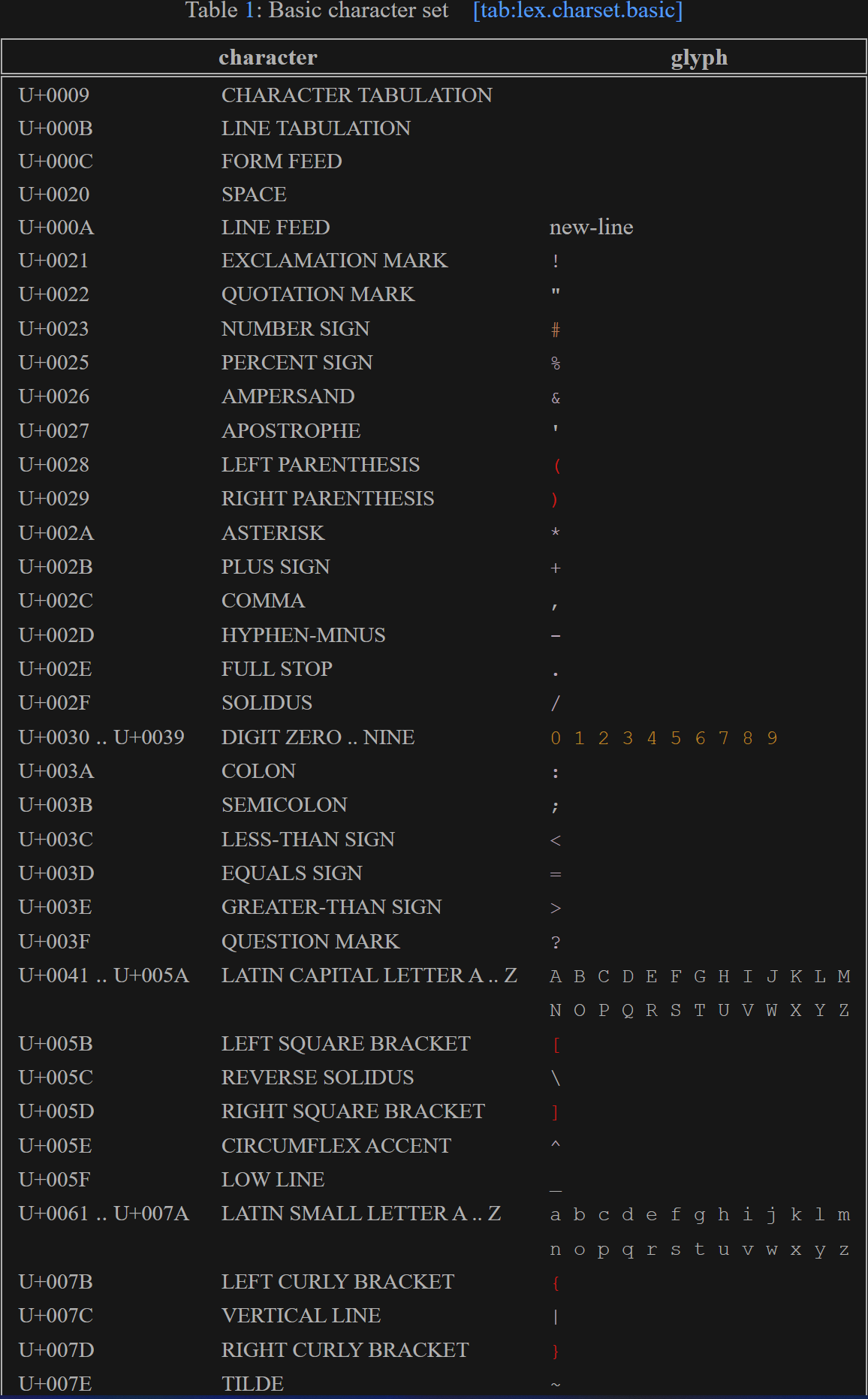
2. ' \ ' 문자 해석하기
#define Test(a, b) \
{ \
if(a != b) \
{ \
a = b; \
} \
};
3. 전처리 토큰들로 분리
=> 소스 파일을 주석, 공백문자, 전처리 토큰 으로 분리하는 단계.
4. 전처리 실행 단계
=> #include 파일 내용 복사.
=> #define 코드 치환
=> #if, #ifndef 코드 치환
=> #pragma .... 등 컴파일러 명령문 해석.
=> #include 로 복사된 내용은 1 ~ 4 번까지 과정을 반복.
=> 해당 과정을 더 이상의 전처리기문이 없어질 때까지 반복.
5. 실행 문자 셋으로 변경
6. 인접한 문자열 합치기
*컴파일 단계
7. 해석 유닛 생성 ( Translation Unit )
=> 전처리기 토큰 -> 컴파일 토큰 으로 변환.
=> 컴파일러가 컴파일 토큰을 해석해 해석 유닛 ( TU ) 생성.
해석 유닛 (TU) 는 각 소스파일 별로 하나씩 존재하게 됨.
8. 인스턴스 유닛 생성 ( Instantitation Unit )
=> 컴파일러가 TU 를 분석해 템플릿 인스턴스 확인.
=> 템플릿들의 정의 위치가 확인되면 해당 템플릿들의 인스턴스화가 진행.
이를 통해 인스턴스 유닛 생성.
=> 8단계까지 완료 후, 컴파일러는 목적코드 ( .obj ) 를 생성할 수 있게 됨.
*정의 ( Defination ) / 선언 ( Declaration )
* 유일 정의 규칙 ( One Definition Rule )
=> 'TU' 에 존재하는 모든 변수, 함수, 클래스... 등의 정의는 '유일' 해야함.
=> inline 이 아닌 모든 함수의 변수들의 정의는 전체 프로그램에서 '유일' 해야함.
=> '선언은 여러 개 있어도 상관없다.'
int number; // 선언 & 정의
void Foo(); // 함수의 선언
void Print() { } // 함수의 선언 & 정의
class Player; // Player class 선언
class Player {} // Player class 선언 & 정의
extern const int a; //선언
extern const int b = 1; //선언 & 정의
//기본적으로 변수는 선언&정의 가 같이 되어지지만
//extern 키워드를 사용해 선언만 가능하도록 할 수 있다.
struct TT
{
static int i; //선언
};
int TT::i = 10; //정의=> 클래스 내부의 static 변수는 클래스 내부에서 초기화될 수 없음.
클래스 선언 자체가 정의가 아니기 때문에 static 변수를 정의할 수 없음.
extern int a;
extern int a;
extern int a;
extern int a;
extern int a;extern int a;
int a = 10;=> 컴파일 가능.
*다시 정리하면
각 소스파일마다 TU (Translation Unit) 이 생성되고 모든 TU 안에서
선언은 여러번 가능하지만, 정의만은 '유일' 해야함.
기본적인 변수는 선언이 곧 정의.
함수는 선언부 / 정의부 분리.
따라서, 이와 같은 이유로
우리는 여러번의 정의를 피하기 위해서
헤더파일에 선언부만 정의해놓고 해당 cpp 파일이 필요하다면
그 헤더파일이 다른 파일들에게 include 하며 선언되어지게 하고
( 선언은 여러번 해도 상관없기 때문. )
해당 함수가 존재하는 cpp 파일 ( 단 하나의 '유일' ) 에는 정의부를 구현함으로써
모든 함수들에게 선언은 되어있지만 정의는 한번 되어지게 만들 수 있다.
또한, 선언되어진 변수, 함수, 클래스... 등은 헤더파일만 추가함으로써 사용 가능하다.
*inline
=> 보통 함수 앞 키워드로 붙게 됨.
inline void PrintFF() { }=> 처음 도입되었을 때, 이 함수 호출을 해당 내용으로 치환시켜라는 의미였다고 함.
( #define 과 비슷한 맥락. )
=> 현재는 inline 을 적용할지 안할지 컴파일러가 판단해 최적화되어짐.
따라서,
inline 은 '여러 개의 TU 에 정의되어 있어도 상관없다' 라는 의미.
test.h
#pragma once
inline void PrintFF() { }
main.cpp
#include "test.h"
int main()
{
}=> inline 을 붙이지 않았다면 에러가 났을 것임.
왜냐하면, PrintFF( ) 함수가 2번 정의되었기 때문에.
=> 이와 반대로, inline 이 붙지 않은 함수들은
전체 TU 에 정의가 반드시 '유일' 해야함.
*추가적인 내용
1. inline 으로 선언된 함수의 선언 과 정의를 분리하게 되면 에러.
test.h
inline void PrintFF();
test.cpp
#include "test.h"
void PrintFF() {}
main.cpp
#include "test.h"
int main()
{
PrintFF();
}
2. 클래스 내부에 정의되어 있는 함수들은 자동적으로 inline.
class Test
{
public:
void PrintFF() {} //자동적으로 inline
};
*오브젝트 파일 ( .obj ) 구성
=> 컴파일 단계에서 재배치 가능한 오브젝트 파일을 생성한다.
( relocatable obj file )

=> 오브젝트 파일 포맷은 시스템마다 다르다.
윈도우즈 계열 시스템의 경우,
Poratble Executable 이라 하는 PE 파일 형식 파일 생성.
리눅스 계열 시스템의 경우,
Executable and Linkable Format, = 'ELF'라 불리는 형태의 실행 파일 생성.
*ELF 기준
@오브젝트 파일 헤더
=> 시스템 속성 정보 저장, 링커가 이 파일을 읽어서 분석할 때 알아야하는 정보들.
@코드 세그먼트 ( .text )
=> 기계어로 변환된 코드.
@데이터 세그먼트
=> 데이터 영역 변수들
=> .rodata ( 읽기 전용 값 ) / .data (초기화된 전역변수 ) / .bss (초기화되지 않은 전역변수)
@심볼 테이블 ( .symtab )
=> 해당 obj 파일 안에 정의, 참조하는 모든 심볼들의 정보.
@재배치 정보 ( .rel.text , .rel.data )
=> 재배치가 필요한 .text, .data 섹션 내 메모리 위치 정보
=> 각 재배치 개체마다 미리 재배치 타입을 판별.
예를 들어,
외부 함수를 호출, 전역 변수 참조하는 명령어들. (.rel.text )
코드 섹션에서 c = a + b; ( a , b, c 는 전역변수 참조 ), printf(...)
외부 함수, 전역 변수의 주소로 초기화되는 전역변수들. ( .rel.data )
@디버그 정보 ( .debug )
=> 디버깅에 필요한 정보.
*결론
컴파일의 대략적인 과정은
전처리기 단계 ( 문자해석, #include, 문자열 합치기 ..등 ) 을 거쳐
본격적인 컴파일 단계에 이르게 되는데,
이 때, 문법적인 오류가 없다면 각 cpp 파일마다 TU ( Translation Unit ) 생성.
TU 에 중요한 규칙은 ODR (유일 정의 규칙) 이다.
선언은 여러 번이어도 상관없지만 정의는 유일해야한다는 규칙을 적용하고 나면
각각의 TU 별로 어셈블리 코드 ( .obj ) 를 생성한다.
이 때, 어셈블러 가 생성한 파일을
'재배치 가능 오브젝트 파일' 이라고 한다.
( relocatable object file )
=> 해당 obj 파일의 심볼들의 정보는 아직 정해지지 않음.
왜냐하면 하나의 실행파일로 합쳐진 곳안의 위치가
심볼들의 최종적인 위치가 되기 때문.
또한, 어딘가 유일하게 정의된 심볼들을 참조하고 있는 심볼들은
정의된 심볼들의 위치조차 알지 못하고 있음.
그로 인해,
코드 영역에서 해당 심볼을 참조하고 있는 명령어들조차 위치 계산을 할 수 없다.
일단은 심볼의 정의가 확정되면 데이터를 어떤 방식으로 재배치해야할지에 대한 정보를
재배치 테이블에 저장하고 있다.
이후 있을 링킹 과정 에서,
모든 obj 파일을 하나로 합치면서 해당 심볼들의 위치들이 정해지고
참조된 심볼들도 재대로 연결시켜주며
해당 심볼 ( 변수, 함수.. ) 들을 쓰고 있는 코드들을 적절한 재배치 방식을 통해
최종적으로 모든 코드들이 정확한 데이터 위치를 찾아가도록 하게끔 만들어주게 됨.
참고 링크
https://people.cs.pitt.edu/~xianeizhang/notes/Linking.html
'프로그래밍 > 부록' 카테고리의 다른 글
| @DLL 동적 라이브러리 만들기 (0) | 2023.01.30 |
|---|---|
| @C++ 링킹에 대한 이해 (0) | 2022.07.27 |