* CPU ( 중앙 처리 장치, Central Processing Unit )

컴퓨터의 두뇌라고 많이 불리는 CPU 는 실리콘으로 이루어진 반도체, 트랜지스터의 집합체이다.
머리카락보다 작은 트랜지스터들이 모여 만들어진다.
CPU 를 이루는 주요 부품은 ALU, Control Unit, Ragister 가 있다.
대략적으로 CPU 가 하는 일을 살펴보면
메모리에 있는 실행될 프로그램의 코드를 읽어와 명령어를 해석하고 그에 필요한 계산이나 메모리에 적재하는 등의 일을 수행한다.
보통 이러한 작업이 한 번 수행되는 시간을 'CPU 클럭' 이라고 말하고 빠를수록 좋다.
더불어 'IPC ( Instruction Per Cycle )' 란 개념도 존재하는데 이는 한 클럭동안 수행될 수 있는 명령어 개수를 의미한다.
이때도 성능을 더 높이기 위해 'OoOE ( Out-of-Order Execution ) 비순차적 실행' 을 적용시켜 CPU 가 최대한 효율적으로 움직일 수 있도록 유도한다.
현재에는 클럭과 IPC 를 늘려 속도를 높이는데에 한계에 부딪히는데 이는 빨리 수행되게하는만큼의 발열이 발생하기 때문이다.
이제는 관점을 바꾸어 CPU 코어를 여러 개 배치하는 방식, 다중 코어 방식으로 CPU 속도 향상을 꾀한다.
CPU 는 어떻게 연산을 수행할까 ??
대부분 컴퓨터는 2진수밖에 모르고 아주 빠른 속도로 계산한다고 말하는데 왜 2진수를 사용해야만했을까 ??
컴퓨터가 동작하기 위해서는 반드시 전기가 필요하다. 우리는 전기와 우리가 계산하는 방식과 엮기길 원한다.
이 때,
우리는 전기가 통하고 있느냐 통하지 않느냐 를 0, 1 로 구분 짓게 만들어 계산할 수 있음을 깨닫게 되고
이 과정을 수행할 수 있게 해주는 중요한 부품인 '트랜지스터' 가 존재한다.
( 트랜지스터에 관해서는 앞 단원에서 설명했다. )
* 논리 회로
트랜지스터의 발달과 함께 컴퓨터에게 연산 능력을 부여하기 위해 '부울 대수학'을 이용한 연산을 사용한다.
이는 참, 거짓 두 가지 경우를 연산으로 이용하도록 발달된 학문이며 '조지 부울' 이란 영국의 수학자에 의해 발명되었다.
아래는 부울 대수를 이용한 연산을 그림으로 표현한 것이다. 여러 종류가 존재한다.
대표적으로 많이 쓰이는 기호는 중간에 ANSI 에서 발표한 논리 게이트이다. 우리가 사용하는 대부분은 이것이다.
'NOT ( 부정 )' 을 뜻하는 경우 앞에 동그라미가 추가되며 AND, OR, XOR 모양은 각각 차이가 존재한다.
* ALU ( Arithmetic and Logical Unit, 산술 논리 장치 )
위 그림은 논리 회로들로 이루어진 부품 ALU 표기 모양이다.
A, B 를 통해서 계산되어질 비트들을 부여받고 왼쪽 Operation Code 에서 어떤 연산을 수행할 것인지를 ( Logical Unit ) 부여받는다.
기본적으로 이 연산 코드는 ADD ( 1000 ) , SUBTRACT ( 1100 ) 로 나타낼 수 있고 이를 이용해 곱셈과 나눗셈을 수행한다.
오른쪽 Status 에서는 특정 상태나 상황들에 대해서 일련의 신호를 출력하기도 한다.
대표적으로 'OVERFLOW ( 마지막 CARRY 값이 존재하는지 )' , 'ZERO ( 해당 값이 0 인지 )', 'NEGATIVE ( 비교 후 음수 신호 반환 )'등을 출력한다.
최종적으로 ALU 는 두 비트의 연산을 결과값을 출력하게 되는데 어떤 과정을 통해 결과 값이 도출되어지는지 알아보자.
* 반가산기 & 전가산기
가산기는 말그대로 덧셈을 계산한다.
CPU 의 ALU 에서 모든 연산의 중요한 핵심 연산은 '덧셈' 이기 때문에 논리 회로로 이루어진 덧셈 계산기를 만든 것이다.
( 빼는 연산을 수행하는 감산기의 경우, 가산기를 이용하기 위해 '2의 보수' 방법을 활용한다. )
이 때, 입력 값에 따라 두 가지 가산기로 나뉠 수 있는데 반가산기 ( Half-Adder ) 와 전가산기 ( Full-Adder ) 가 그것이다.
반가산기와 전가산기를 살펴보기 전에 몇 가지 알아야할 기호들이 존재한다.
A, B 는 ALU 가 가산기에게 주어준 해당 자리 수의 비트이며,
S 는 해당 비트 자리 수의 값이고 C 는 앞 자리 비트에 넘겨줄 자리 올림 비트를 의미한다.
Dot Product 와 같은 기호는 AND 연산을 나타내며 큰 더하기 기호에 원 모양은 XOR 연산을 의미한다.
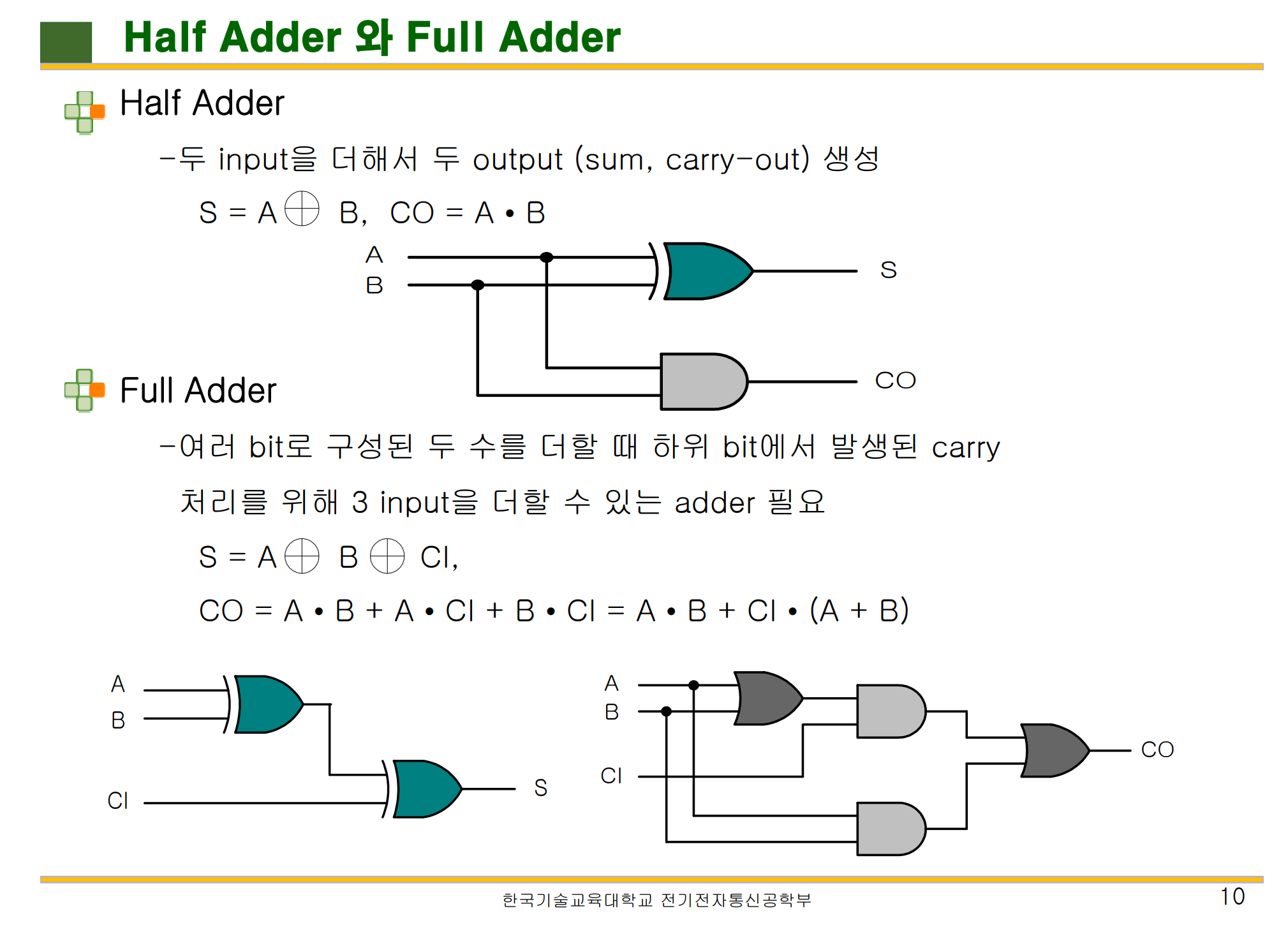
그림에서 보는 것처럼,
반가산기와 전가산기의 중요한 차이점은 '입력 값에 존재'한다.
반가산기는 입력 값이 A,B 2개뿐이다. 이는 C ( 자리올림 ) 값이 필요없기 때문에 비트 계산의 첫 번째 자리 수에 쓰일 수 있다는 의미이다.
반면, 전가산기는 입력 값이 A,B,C 총 3개이다.
이는 이전에 위치한 가산기의 C ( 자리 올림 ) 값을 받아서 논리 연산을 수행한다. 반가산기보다 논리 회로가 더 쓰이는 것을 볼 수 있다.
따라서, 위 연산을 통해 S ( 현재 위치 비트 ), 와 C ( 현재 비트 자리 올림 ) 값을 구할 수 있다.
여기까지 보았을 때, 우리는 간단하게 위 가산기를 이어붙이면 비트 연산이 수행될 것이란 생각이 든다.
이것이 '리플 캐리 가산기' 이다.
* 리플 캐리 가산기 ( Ripple Carry Adder )
Ripple 이란 파도를 의미하는데 Carry 값이 순차적으로 옮겨가는 현상을 보고 지은 이름이라고 한다.
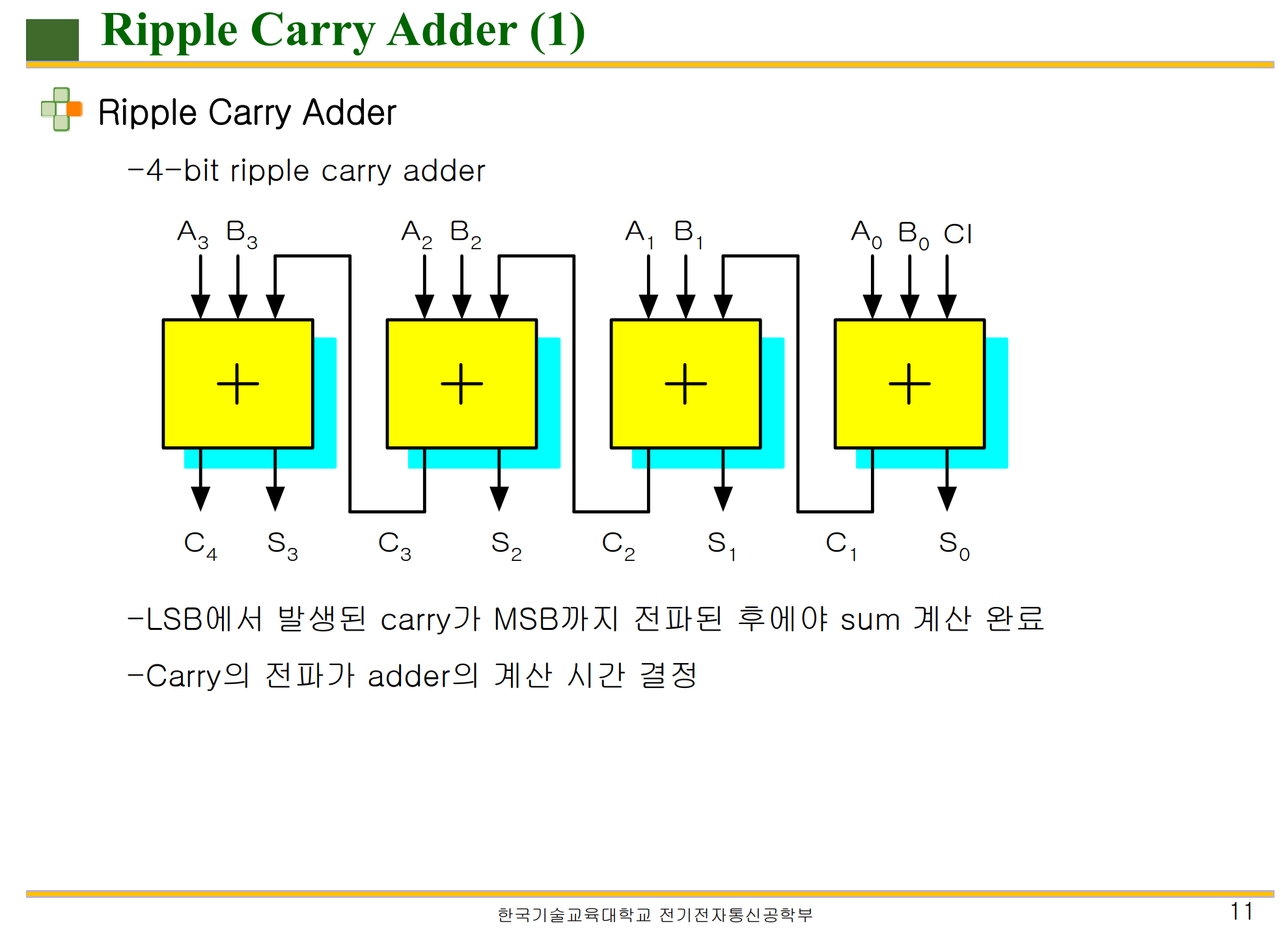
'리플 캐리 가산기' 란 첫 번째 비트 연산에 반가산기, 이후로 전가산기를 배치하면서 수행되는 가산기 형태이다.
( 위 그림에선 전부 전가산기가 쓰였다. )
특징으로는 C4 값을 얻기 위해선 이전의 C3 값을 받아야하기 때문에 총 Ci, C1, C2, C3 까지의 과정을 거쳐야한다는 것이다.
이 방식은 연산할 비트 자리수가 많아질 때마다 큰 폭의 속도 저하를 가진다.
이를 해결하기 위한 방법이 '올림수 에측 가산기' 이다.
* 올림수 예측 가산기 ( Carry Look AHead )
CLA ( Carry Look Ahead ) 에서 추가되는 개념이 존재하는데 G ( Generate, 생성 ), P ( Propagate, 전달 ) 이 그것이다.
G 의 의미는 자리 올림이 확실한 상태를 의미하는데 각각 A,B 비트가 1, 1 일 때에 해당한다.
P 의 의미는 자리 올림이 발생할 수 있는 상태를 의미한다.
예를 들어, A, B 비트가 0,1 / 1,0 일 때는 이전의 C ( 자리 올림 ) 에 의해서 현재 자리의 C 값이 발생할 수 있는 상황이다.
따라서,
G 는 A, B 를 AND 함으로써 얻을 수 있고 P 는 A, B 를 XOR 함으로써 얻을 수 있다.
우리는 해당 비트 자리수의 S ( 현재 비트 자리 값 ), C ( 현재 비트 자리 올림 ) 값을 구하는 것이고
리플 캐리 가산기의 비효율을 해결하기 위한 방법 위에 있다.

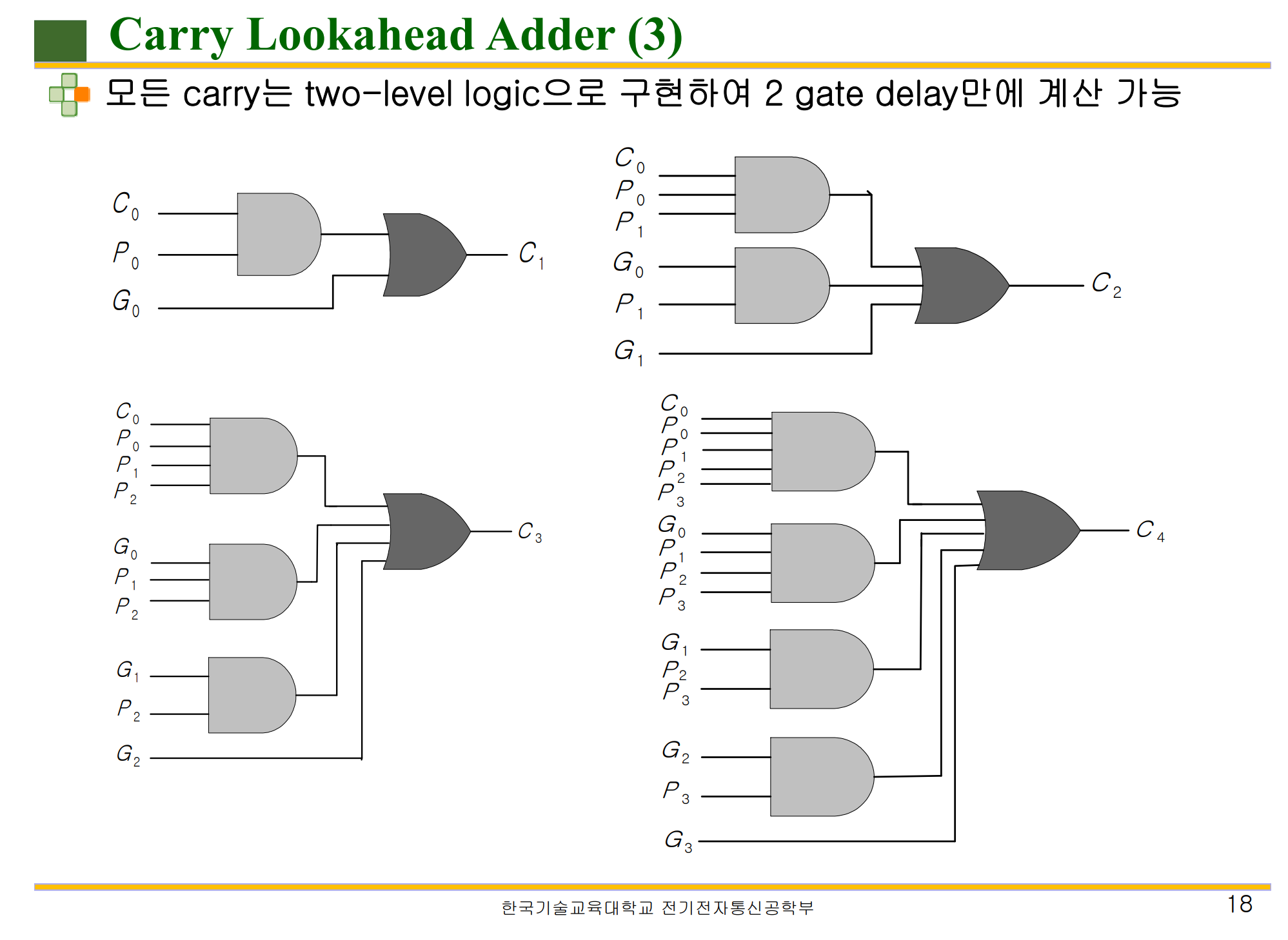
중요한 것은 '어떻게 C 의 값을 미리 구할 수 있는가' 이다.
이는 모든 비트 자리의 A, B 를 모으는 Block 을 두고 G, P 를 계산한다. 이 후 G, P, A, B, C0 ( 첫번째 비트 자리올림 ) 으로 해당 자리의 C 값을 구할 수 있다.
첫 번째 그림이 해당 점화식이다.
이어 두번째 그림은 CLA 에 필요한 논리회로가 그려진 그림인데 보다시피 높은 자리에 있는 비트일수록
필요한 정보가 많기 때문에 논리회로가 복잡해질 수 밖에 없다.
기본적인 식은 S = P ( XOR ) C , C = G ( XOR ) ( P ( AND ) C ) 가 된다.
이를 각 자리의 C0 ~ C4 까지 점화식으로 정리한 것이다.
논리 회로를 거치는 단계를 'd' 라고 정의하고 4 bit 연산을 사용한다고 가정할 때,
리플 캐리 가산기 에서는 4 bit 까지 4d ( 단계적 ) 가 소요되는 반면,
CLA 에서는 4 bit 까지 3d 가 소요된다. ( G, P 를 구하는 과정 + AND 과정 + XOR 과정 )
더 많은 bit 수 예를 들어 16 bit 일 때의 리플 캐리 가산기는 16d 가 소요되는 반면,
CLA 에서는 일관적으로 3d 가 소요된다. 다만 논리회로가 늘어난다.
이로써
'CLA ( Carry Look Ahead )' 에서는 이전의 C 값을 기다리지 않고 모든 bit 정보 ( A,B ) 를 받아서 P, G 구해 이를 이용해 S, C 값을 계산할 수 있게 된다.
다만 비트가 늘어날수록 복잡해진다는 단점이 있다.
현대의 32bit, 64bit 의 가산기 연산은 리플 캐리 가산기로는 턱없이 부족하고
CLA 방식으로도 로직이 매우 복잡해지기 때문에 이를 블록 단위로 쪼개서 다단계로 구성하는 방법을 사용한다고 한다.
* 레지스터 ( Register )
레지스터는 CPU 가 어떤 명령어를 처리하기 위해서 쓰이는 아주 작은 용량의 저장소이다.
CPU 에는 레지스터를 하나만 가지고 있지 않고 여러 개를 가지면서 레지스터는 각각의 다른 역할을 수행한다.
예를 들어,
현재 실행되고 있는 프로세스의 명령줄 위치를 저장하는 레지스터 ( PC ), 명령어를 저장하는 레지스터 ( IR ), 그외에
연산을 위해 필요한 eax, ebx, ecx, edx 등 다양한 레지스터를 사용한다.
여기서 궁금한 점은
레지스터는 어떤 0 과 1 로 이루어진 데이터를 저장하는 역할을 수행하는데 어떻게 0 과 1을 저장할 수 있을까 ??
이 역시도 논리 회로를 이용해서 0 과 1을 저장할 수 있다.
이런 논리 회로를 이용해 만든 추상화 단위를 'LATCH ( 걸어잠그다 )' 라고 부른다.
이 때, 하나의 LATCH 에는 '데이터 입출력선 ( Data In/Out )', '쓰기 가능 선택선 ( Write Enable )' 등이 있다.
이런 LATCH 들을 이어서 만든 저장소가 바로 '메모리' 가 되겠다.
* 메모리 하드웨어 구성
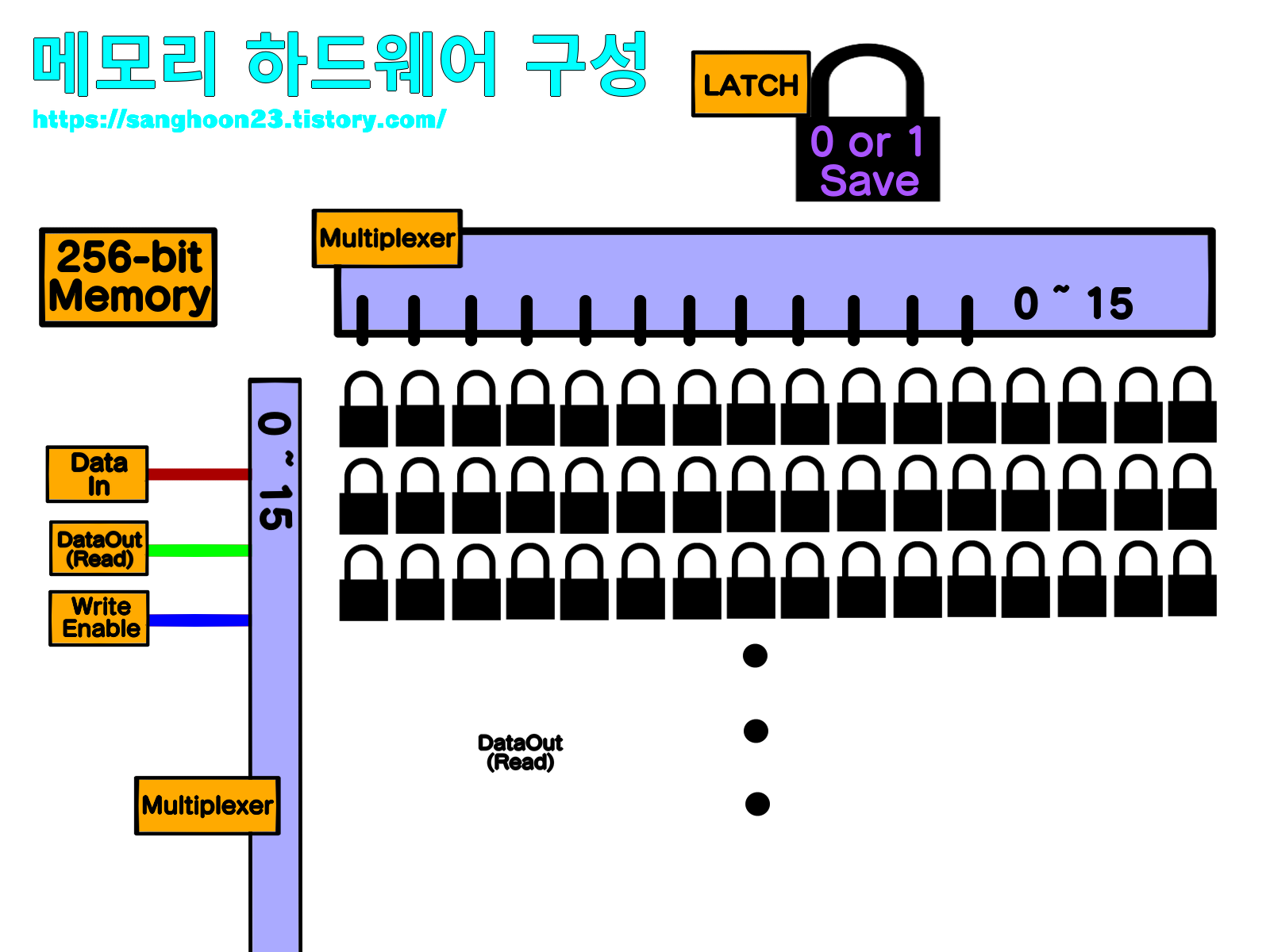
위 그림은 256 bit 를 저장할 수 있는 메모리의 구성을 표현한 그림이다.
256 bit 를 위해서 16x16 로 LATCH 를 이어붙이면 간단하겠지만 문제는 '선의 개수' 이다.
앞서 LATCH 에 선이 3개만 존재해도 이어붙여 구현하게 될 때, 총 768 개의 선이 필요하다.
이를 해결하기 위해서 그림처럼 행렬 ( Matrix ) 형태로 LATCH 를 놓고 찾고자하는 행렬에 해당하는 LATCH 를 찾아내는 방식을 사용한다.
위치를 찾아내는 역할을 '멀티플렉서 ( Multiplexer )' 가 맡는다.
멀티플렉서는 가로, 세로 각각 필요하고 해당 행과 열의 선들을 관리한다.
데이터 입출력, 읽고 쓰기 선택 등 또한 모든 LATCH 에 접근할 수 있게 됨으로써 하나로 통합 가능하다.
결과적으로, 256bit Memory ( 16x16 ) 에서 총 32 + 1 + 1 + 1 = 35 개의 선만을 필요하게 된다.
( 16 ( 가로 ) + 16 ( 세로 ) + 1 ( 데이터 입력 ) + 1 ( Data Out ( Read ) ) + 1 ( WriteEnable ) )
이러한 원리로 레지스터 혹은 더 큰 메모리인 RAM 을 구성한다.
더 나아가서,
부팅 시, OS ( 운영체제 ) 가 RAM 에 올려져 CPU 가 읽는 것처럼 CPU 는 RAM 에 있는 명령어 집합체인 특정 프로그램들을 읽는다.
이 때,
CPU 가 어떤 프로그램을 동작시키기 위해서 RAM 에 접근하게 되며 해당 명령어들을 해석하는 과정이 필요로 하는데
이를 'Control Unit' 에서 수행한다.
* CU ( Control Unit, 제어 장치 )
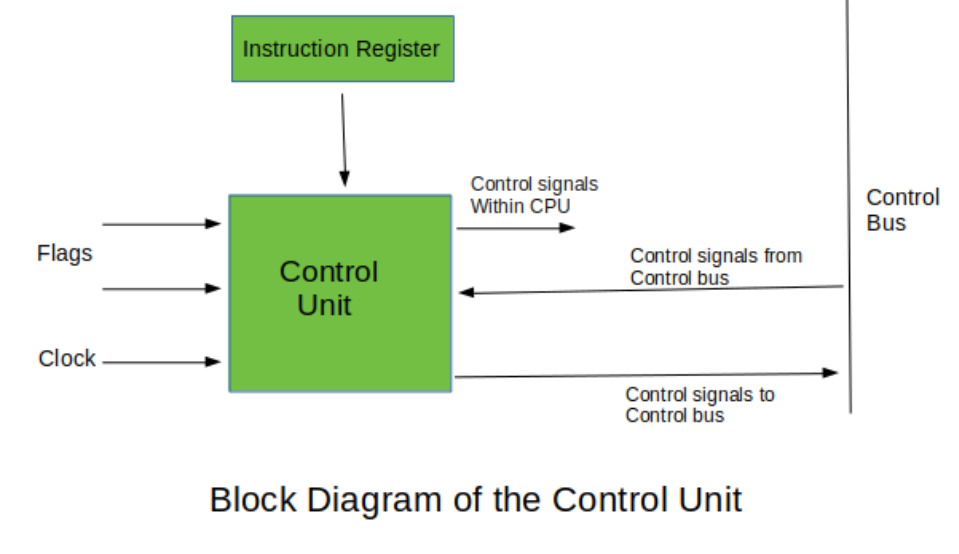
CPU 를 우리의 두뇌와 같다고 하는데 실질적으로 명령어를 해독하는 역할을 수행하는 곳이다.
이 단락에서 눈여겨봐야할 것은 '어떻게 명령어를 해석하고 동작하는가' 이다.
이전에 우리는 해석되어지는 명령어의 형식을 알 필요가 있다.
* RISC / CISC ( Complex, Reduced Instruction Set Computer )
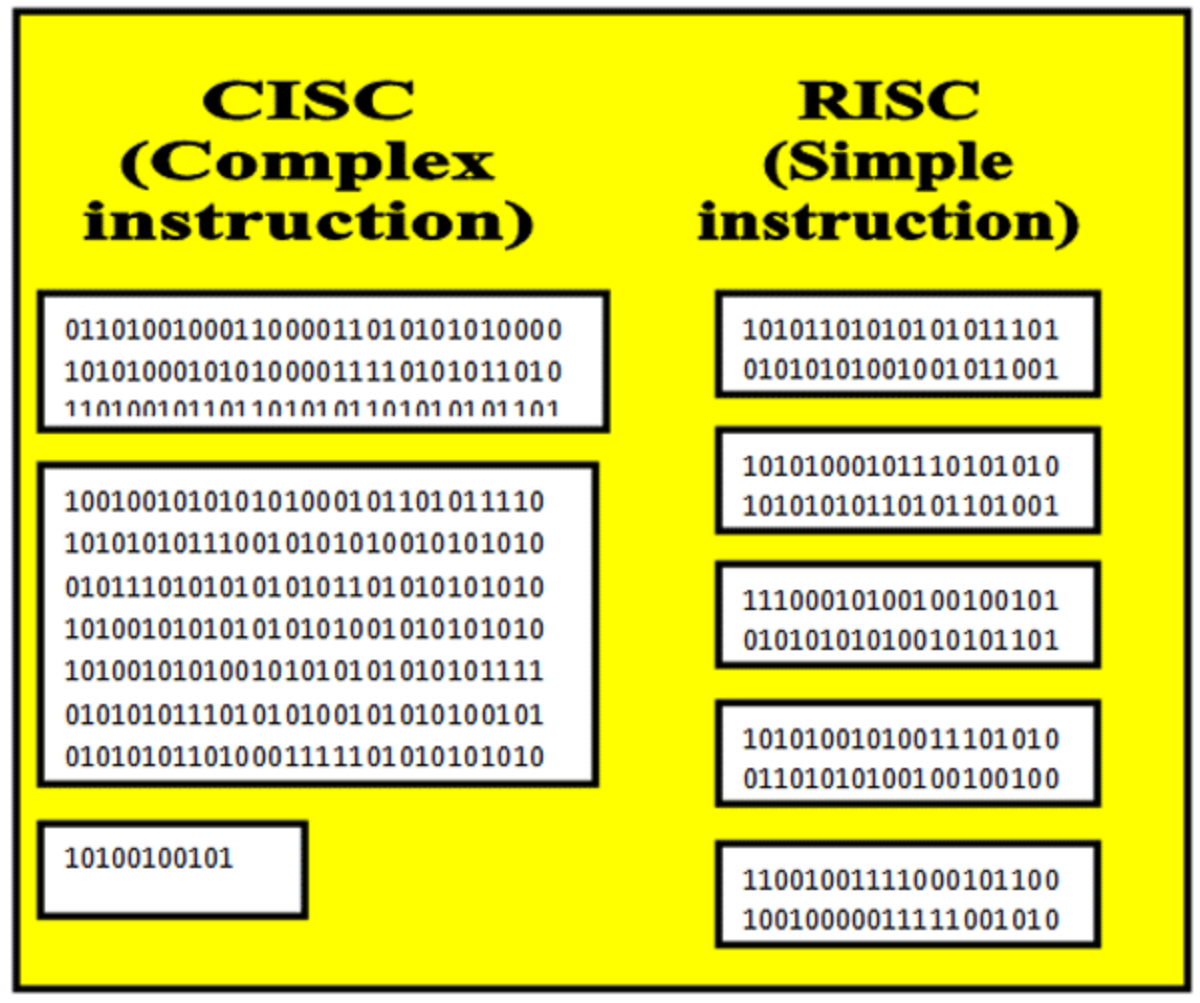
RISC 와 CISC 의 결정적 차이는 '명령어의 길이' 에 존재한다.
CISC 는 명령어의 길이가 가변적이며 하드웨어 단계에서 명령어 호환성이 좋다.
반면 RISC 의 경우, 명령어의 길이가 고정적이며 CISC 에 비해서 속도가 빠르다는 장점이 있다.
초기에 CISC 기반으로 명령어를 처리하다가 CISC 의 기반 명령어 해독 과정이 매우 어려워졌다.
왜냐하면 어떤 명령어가 가변적이기 때문에 어떤 명령어가 들어올지 모르고 명령어 길이만큼 나누는데 시간이 소요되기 때문이다.
또, Decoder 에 할당해야하는 트랜지스터가 많아져 연쇄적으로 낭비된다.
이런 여러가지 이유로 RISC 가 등장했다.
현재는 RISC 와 CISC 를 적절히 혼합해서 사용하고 있고 명확하게 구분짓기 어렵다고 한다.
또한 두 방식에서 엄청난 속도 차이가 나지 않는다하며 현재는 CPU Clock 속도를 올리는데 한계가 있다고 말한다.
위 처리 방식에 따라 하드웨어적 Control Unit 도 두 가지 방식이 존재한다.
'Hardwired' 와 'Micro-programmable' 방식이 그것이다.
* Hardwired Control Unit
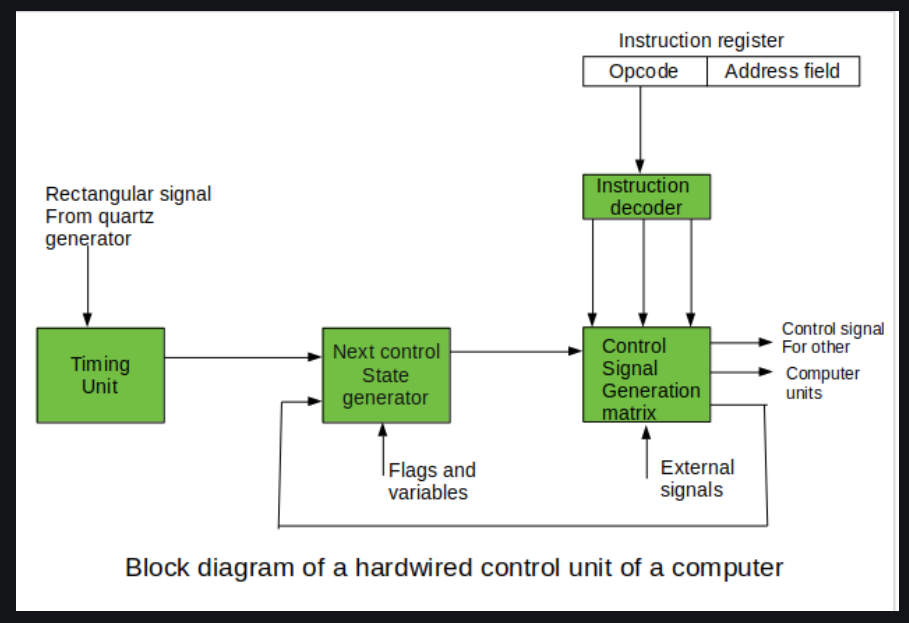
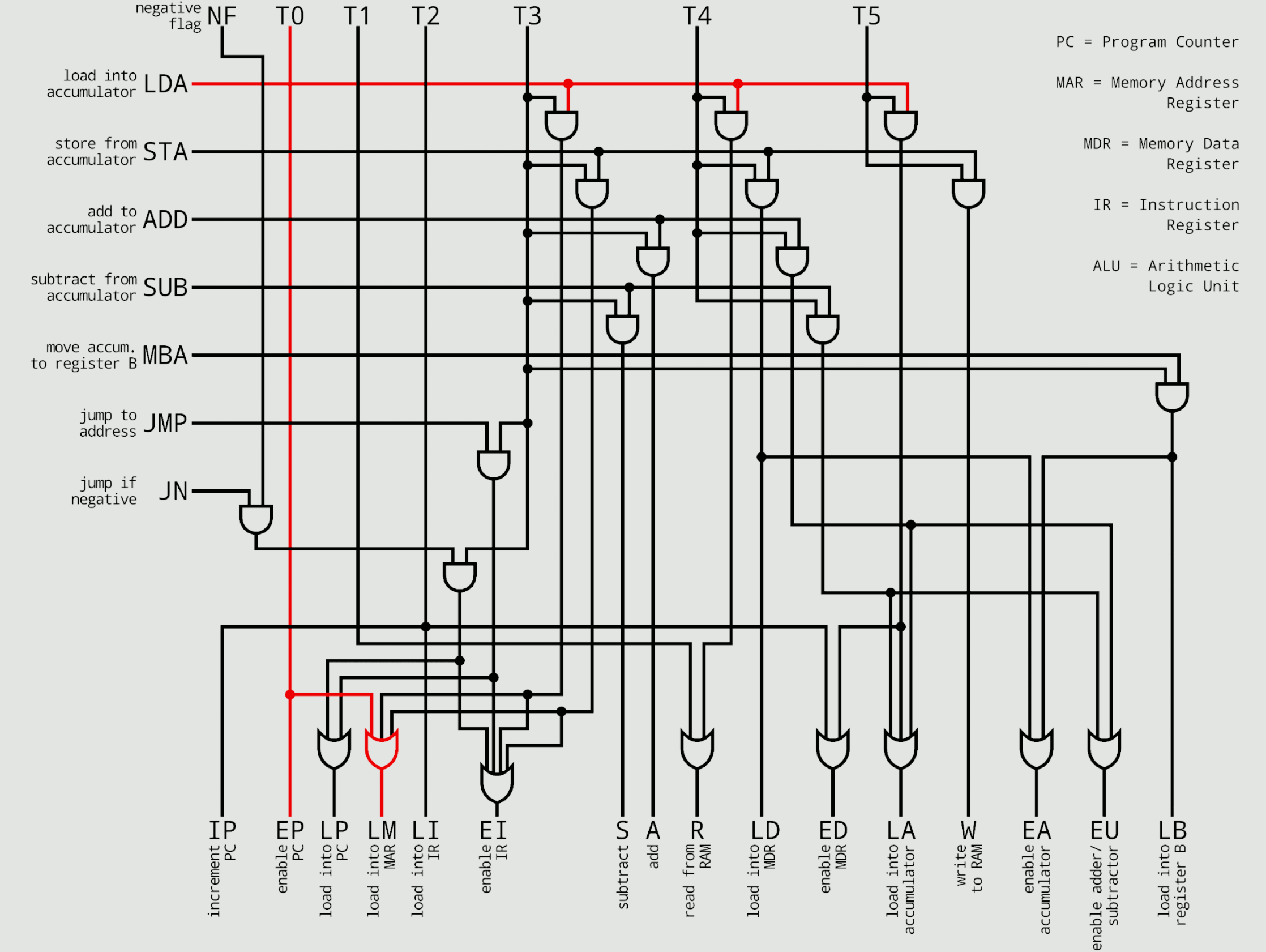
기본적으로 하드웨어 내장 방식에서의 명령어는 Opcode 가 고정적이라 빠른 명령어 해석이 가능하다.
이를 명령어 해독기 ( Instruction Decoder ) 에서 실행한다.
Decoder 에서 출력된 결과 값을 통해 각종 하드웨어 장치들이 받아들일 수 있는 신호를 생성하고 보내진다.
여기서 중요한 과정 중 하나는
'Matrix' 라는 일종의 테이블 형태로 제어 신호와 처리 방식들을 조합해 종합적인 신호를 만들어 내는 것이다.
이 과정 이전에, 현재 Control State ( 상태 ) 를 확인하며 Timing Unit 에서 어떤 작업을 수행하는지 고려한다.
Timing Unit 은 Memory 혹은 I/O 장치에 읽고 쓰는 신호, RESET, Halt ( 종료 ), Opcode fetch 신호 등 제어 신호를 만들어내는 부품으로 보인다.
이 후, 생성된 제어 신호를 제어 버스를 통해 전달되며 프로그램 상태에 맞는 작업들이 수행된다.
계속해서 다음 명령어를 IR ( Instrcution Register ) 에서 읽어들이며 반복한다.
또, 외부 신호로 인터럽트가 발생할 수 있고 여러가지 조건( if,switch.. ) 과 분기 형식 ( JMP... )과 혼합된다.
이에 따라서,
'명령어 연산 방식들이 각각의 상황에 따라 수행 방식이 다를 수 있다' 는 의미를 유추할 수 있다.
전체적인 구조를 보았을 때, Hardwired Control Unit 은
CU 의 상태를 저장하면서 CPU Clock Cycle 을 수행할 때마다 해당 상태를 고려해 다른 상태로 넘어가는 State Machine방식과 유사하게 보여진다.
위 그림의 2번째 그림이 위 아키텍처 ( Matrix ) 를 만들어 놓은 것이다.
결론적으로 위 Hardwired 방식은
하드웨어에 입력된 내장 아키텍처의 방식에 따라 처리되기 때문에 명령어를 해독하는 시간이 다른 가변적 명령어 처리에 비해 빠르지만
해석해야하는 명령어가 추가되거나 변경 사항이 존재할 때마다 구조를 손봐야하므로 유연성이 떨어진다.
* Microprgrammable Control Unit
https://www.geeksforgeeks.org/computer-organization-hardwired-vs-micro-programmed-control-unit/?ref=lbp
앞서본 Hardwired 방식과 또 다른 방식의 명령어 해석 방식이다.
이 두 방식의 근본적인 차이점은 'Control Store' 의 유무이다.
명령어의 길이가 가변적이고 많은 수의 명령어를 구별해야하기 때문에 Control Store 를 통해 관리한다고 유추할 수 있다.
이 명령어들을 'Control Memory' 라는 특별한 메모리 영역에 따로 저장한다. ( RAM or ROM 에 저장되어있다고 함. )
이로 인해,
많은 명령어들을 구별할 수 있고 호환성이 뛰어나지만 Control Memory 에서 명령어를 인출하는데의 시간이 추가적으로 소요된다.
대략적인 해석 과정을 알아보자.
IR 에 담겨진 명령어는 Control Store 의 MicroInstruction Address Register 에 보내져 해당 주소의 명령어를 해석한다.
이 후, Decoder 거쳐 Control Memory 를 참조해서 명령어를 해석한다.
여기서 말하는 MicroInstruction 이란 CM 에 정의되어진 명령어들을 말하고
MicroProgram 은 해당 명령어들의 집합체로서 추상화된 것처럼 보인다.
명령어 해석 과정에서 Control Store 에 저장된 MicroInstrcution 을 알아내며 여러가지 필드로 분해할 수 있다.
총 연산 필드, 조건, 분기, 주소 필드로 이루어져있다.
Operation part ( 연산 필드 ) 는 Microinstruction 안에 포함된 암호화된 제어 신호 부분이며 전기 신호를 만들어낸다.
하드웨어에 따라서 여러 개의 연산 필드가 존재할 수 있고 동시에 실행된다.
아래 그림에 표기된 Control 필드는 각각 조건, 분기 필드로 나뉠 수 있다.
조건 필드 는 분기에 사용될 조건 플래그를 지정한다.
if, switch 의 조건 명령과 앞서본 ALU 에서 Status 의 NEGATIVE ( 비교 ) 와 같은 조건 등을 판별하는 곳이다.
분기 필드 는 다음에 실행할 Microinstruction Address 를 결정하는 방법을 표기한다.
( JMP, CALL, RET, MAP )
마지막, Address 부분 은 분기가 발생할 때, 목적지 Microinstruction Address 로 사용한다.
예를 들어, JMP 분기 명령일 때 해당 주소로 JMP 를 수행한다.
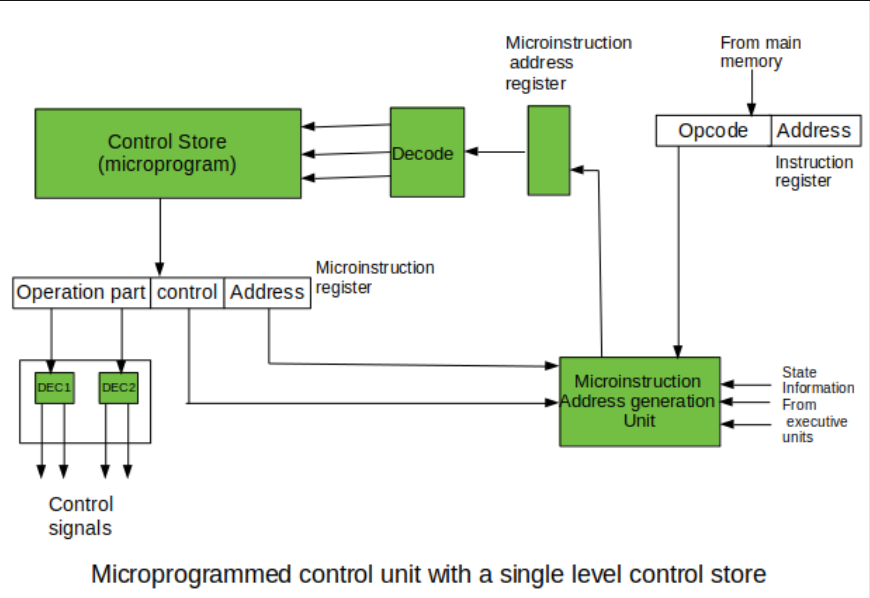
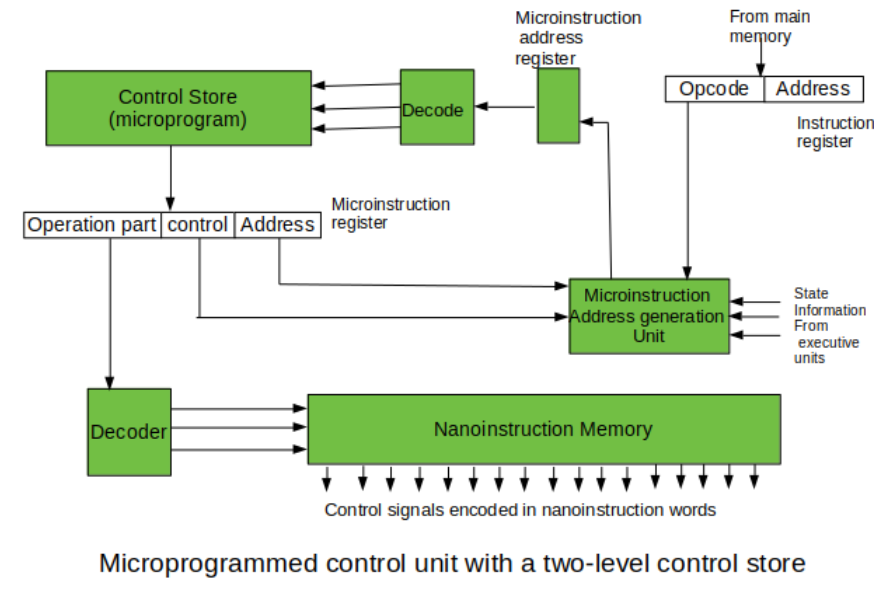
Control Store 를 거치는 단계를 1단계, 2단계로 나누어서 구현할 수 있다.
위에서 설명한 과정은 Control Store 을 한번만 거치는 과정으로 첫 번째 그림이 나타낸다.
두번째 그림에서는 추가적인 단계를 구현하는데,
앞서 1단계와 다르게 2단계로 구성된 방식에서는 Operation part 해독을 다른 곳에서 수행한다.
Operation 연산이 저장되는 nano-Instruction Memory 가 따로 존재한다.
이런 제어 신호를 저장하는 메모리를 구별해놓은 이유는 CM 에서 중복되는 '연산 필드' 때문이다.
같은 연산마다 조건, 분기 필드가 수행될 수 있는 경우의 수가 존재하기 때문이다.
결과적으로, Control Memory 크기가 더 늘어나 낭비된다.
이를 방지하고자 Control Signal 생성을 위한 nano-Instruction Memory 에 연산 내용을 따로 저장하여 전체적인 메모리를 줄이고
역할이 분리되어 Operation part 를 해독하는 동안 기존 Microprogram 에서는 다른 명령어를 해석할 수 있다.
nano-Instruction Memory 가 독립적이라서 새로운 Operation 추가에는 더욱 유연하다.
하지만, Decoder 를 하나 더 만듦으로써 더 많은 트렌지스터를 요구하며 최종적인 제어 신호를 얻기에 느리다.
* CPU 의 전체적인 동작 과정
이제까지 살펴본 ALU, CU, Register 를 추상화해서 전체적인 그림을 그려보자.
그전에 간단한 용어 정리가 필요해보인다.
Page : 운영체제가 프로그램의 가상 메모리를 일정 단위로 나눈 Block.
( 32bit 에서는 4K 크기라고 하며 운영체제마다 다르다. )
Cache Memory : RAM 까지의 전기 신호가 매우 멀어서 Memory 에 Wirte / Read 할 때 CPU 지연이 발생한다.
이를 해결하기 위해 놓은 CPU 옆의 메모리이다. RAM 에 접근할 때 일정 부분의 데이터를 가져온다.
Cache Hit : 사용될 데이터가 캐시 메모리에 존재하는 적중률이다.
MMU : 운영체제의 페이징 기법을 위해 가상 메모리의 위치를 실제 물리 메모리 위치로 변환시켜주는 역할을 수행한다.
OS 가 관리하는 페이지 테이블에 접근해 데이터를 가져온다.
TLB ( Translation Lookaside Buffer ) : MMU 가 페이지 테이블에 접근하는 시간 또한 오래 걸려서 이를 해결하기 위한 임시 메모리이다.
( 물리 메모리 저장에 대해 Cache 메모리와 비슷한 역할을 수행한다. )
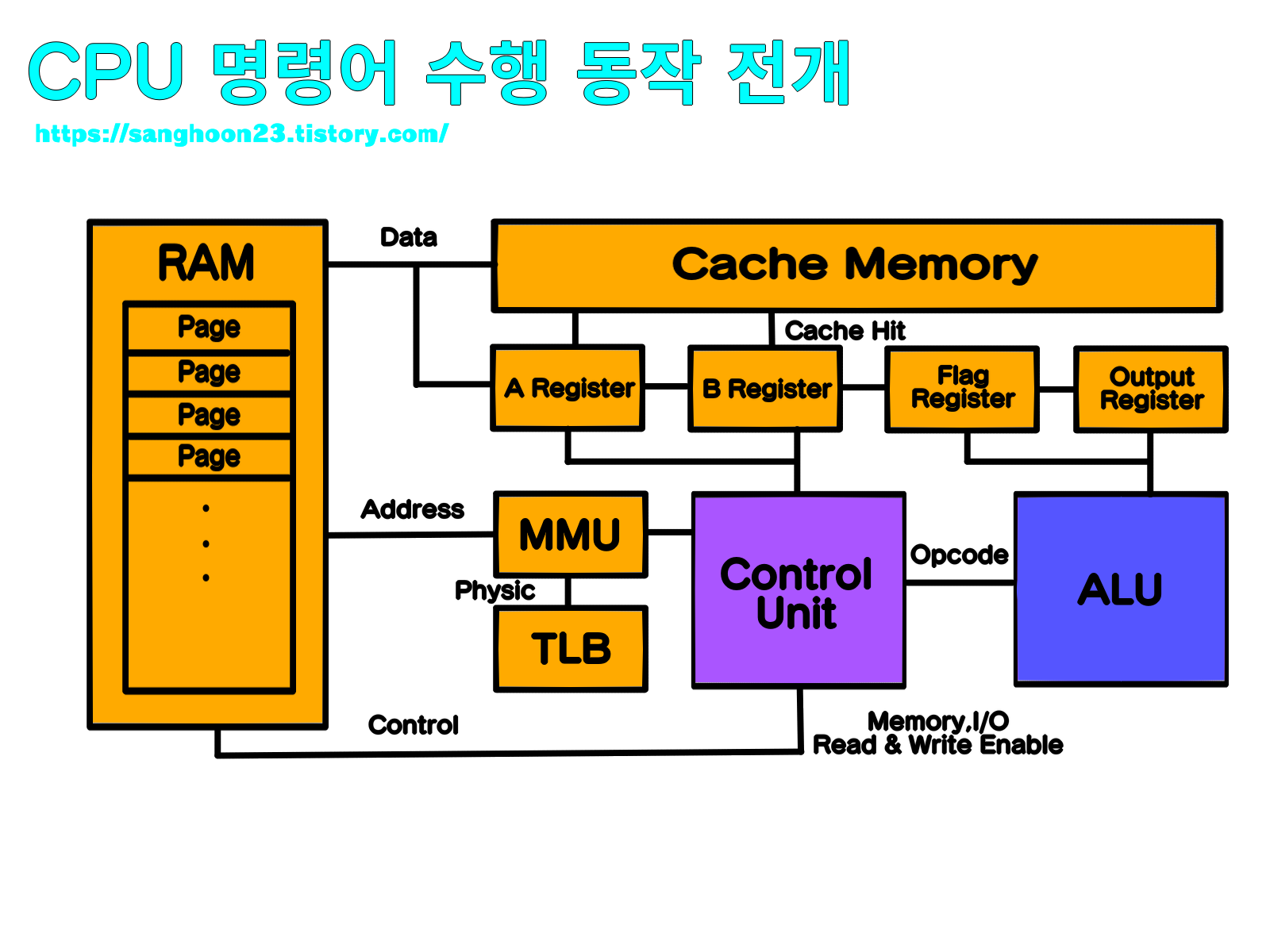
처음에 CU 는 Address Bus 를 통해 명령어를 가져오는 것부터 시작한다.
물리 주소는 CPU 가 현재 수행하는 프로그램의 가상 주소로 바뀌게 되며
해당 명령어와 주소는 CU 안의 IR ( Instruction Register ), Address Register 에 저장된다.
명령어 해석 방식에 따라 ( RISC, CISC ) Control Unit 은 그에 따른 내부적 작업을 수행하며 ( Hardwired, Microprogrammable )
해석된 명령 부분을 제어 신호로 변환해서 Control Bus 에 보낸다.
또 현재 상태에 따라서 어느 레지스터를 써서 값을 저장해놓을 것인지 이 후 가져올 값의 주소는 어디 있는지 판별하고
연산 과정이 필요하다면 ALU 에게 명령어를 전달해 수행되도록 한다.
나오는 결과 값은 레지스터에 로드되고 Data Bus 를 통해 전달하고 이전에 Control Bus 에 전송된 명령을 통해
이 값이 메모리에 쓰이는 것인지 I/O 에 필요한 정보인지 판별한다.
다음 명령어 수행을 위해 RAM 에 접근하기 전 캐시 메모리를 살펴보며 연산 도중의 값이 캐시 메모리에 있을 수 있고
실제 RAM 메모리와의 값이 다를 수 있다. 가져온 명령어를 다시 해독하는 과정을 반복한다.
결국,
CPU 는 RAM 과 상호작용하면서 명령어를 계속 수행하는 장치이며, 프로그래머로써 우리의 역할은 우리가 원하는 작업을 명령어로 만들고
빌드 과정을 거쳐서 명령어을 종합한 명령어 집합소인 프로그램을 만드는 일이다.
더 나아가, 인터넷을 통해서 우리가 만든 프로그램을 다른 여러 사용자들이 자신의 컴퓨터에서 수행될 수 있다.
사용자가 불편을 겪지 않도록 올바르게 명령어를 작성하는 것 또한 우리가 해야할 작업이다.
CPU 가 컴퓨터 내부에서 중요한 역할을 하는만큼 설명하고 이해할 내용도 무척 많았다.
내용이 너무 길어지는 관계로 이번 단락은 이쯤에서 마무리 짓겠다. 하지만 아직 더 재미있는 내용이 남아있다!!
바로 아직 자세히 살펴보지 못한 캐시 메모리와 비순차적 실행 ( OoOE ) 에 관한 내용이다.
더불어, 해당 구조로 인해 범죄까지 이어질 수 있는 멜트다운 ( Meltdown ), 스펙터 ( Spector ) 에 관한 내용도 있다.
이에 관련해서는 다음 단원에서 정리하려고 한다.
참고 자료
'운영체제 & 컴퓨터구조' 카테고리의 다른 글
| [ARCH]#Cache Memory, Meltdown & Spectre (0) | 2023.03.09 |
|---|---|
| [ARCH]#트랜지스터 (0) | 2023.01.26 |
| [OS] #13. RPCs ( Remote Procedure Calls ) (0) | 2022.10.22 |
| [OS] #12. 가상 메모리 ( Virtual Memory ) (0) | 2022.09.16 |
| [OS] #11. 세마 포어 ( Semaphore ) (0) | 2022.09.15 |